从 PVS-Studio 7.14 开始,C 和 C++ 分析器一直支持模块间分析。在这篇由两部分组成的文章中,我们将描述编译器中的类似机制是如何排列的,并揭示我们如何在静态分析器中实现模块间分析的一些技术细节。

前言
在我们检查模块间分析之前,让我们记住编译在 C 和 C++ 世界中是如何工作的。本文重点介绍对象模块布局的各种技术方案。我们还将了解知名编译器如何使用模块间分析以及它与链接时间优化 (LTO) 的关系。
如果您是该领域的专家,您可能会喜欢本文的第二部分。在那里,我们将描述我们的解决方案以及我们在实施过程中遇到的问题。顺便说一句,作者并不认为自己是编译器专家。建设性的批评总是受欢迎的。
编译阶段
C 和 C++ 项目分几个步骤编译。
标准C18(第 5.1.1.2 节“编程语言 – C ”)和C++20(第 .5.2 节“工作草案,编程语言 C++ 标准”)分别定义了 8 个和 9 个翻译阶段。
让我们省略细节,抽象地看一下翻译过程:
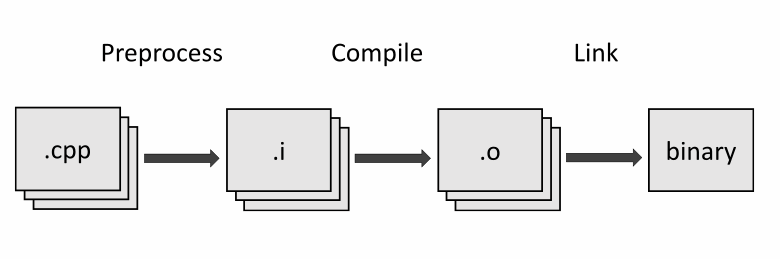
- 预处理器在将每个编译文件传递给编译器之前对其执行初步操作。在这个阶段,所有头文件的文本都被替换为#include 指令并且所有的宏都被展开。对应于阶段 1-4。
- 编译器将每个预处理文件转换成一个带有机器代码的文件,该文件准备好链接到一个可执行的二进制目标文件。对应于阶段 5-7。
- 链接器将所有目标文件合并成一个可执行的二进制文件,同时解决匹配符号的冲突。只有在这个阶段,写在不同文件中的代码才链接为一个。分别对应于 C18 和 C++20 草案的第 8 阶段和第 9 阶段。
如您所见,该程序由翻译单元组成。这些单元中的每一个都是独立于另一个编译的。因此,每个单独的翻译单元都没有关于其他翻译单元的信息。因此,C 和 C++ 程序中的所有实体(函数、类、结构等)都有声明和定义。
看例子:
// TU1.cpp
#include <cstdint>
int64_t abs(int64_t num)
{
return num >= 0 ? num : -num;
}
// TU2.cpp
#include <cstdint>
extern int64_t abs(int64_t num);
int main()
{
return abs(0);
}TU1.cpp有abs函数的定义, TU2.cpp文件有它的声明和使用。如果不违反一个定义规则 (ODR) ,则链接器确定调用哪个函数。ODR 意味着限制:每个符号应该只有一个定义。
为了简化不同翻译单元的协调,创建了头文件机制。该机制包括声明一个清晰的接口。稍后,如有必要,每个翻译单元将通过预处理器#include目录包含一个头文件。
符号及其类别
当编译器遇到一个在翻译单元中没有相应定义的声明时,它必须让链接器完成它的工作。而且,不幸的是,编译器失去了一些它本可以执行的优化。此阶段由链接器执行,称为链接时间优化 ( LTO )。链接通过实体名称进行,即通过标识符或符号。在同一阶段还进行模块间分析。
编译器必须将不同的目标文件合并为一个,同时链接程序中的所有引用。在这里,我们需要更详细地检查后者。我们谈论的是符号——基本上,符号是程序中出现的标识符。看例子:
struct Cat // <Cat, class, external>
{
static int x; // <Cat::x, object, internal>
};
Cat::x = 0;
int foo(int arg) // <foo(int), function, external>
{
static float symbol = 3.14f; // <foo(int)::symbol, object, internal>
static char x = 2; // <foo(int)::x, object, internal>
static Cat dog { }; // <foo(int)::dog, object, internal>
return 0;
}编译器将符号分为几类。为什么?并非所有符号都应该在其他翻译单元中使用。我们需要在链接时牢记这一点。在静态分析中也应考虑到这一点。首先,我们需要确定收集哪些信息以在模块之间共享。
第一类是联动。定义符号范围。
如果符号具有内部链接,则只能在声明它的翻译单元中引用该符号。如果另一个对象模块中存在同名符号,则不会有问题。但是链接器会将它们视为不同的。
static int x3; // internal
const int x4 = 0; // internal
void bar()
{
static int x5; // internal
}
namespace // all symbols are internal here
{
void internal(int a, int b)
{
}
}如果符号具有外部链接,则它是唯一的,旨在用于所有程序翻译单元,并将放置在一个公共表中。如果链接器遇到多个具有外部链接的定义,它会报告违反了一个定义规则。
extern int x2; // external
void bar(); // external如果符号没有链接类型,那么它将仅在定义它的范围内可见。例如,在具有自己范围的指令块中(if、for、while等)。
int foo(int x1 /* no linkage */)
{
int x4; // no linkage
struct A; // no linkage
}第二类——储存期限。标识符的属性定义了创建和销毁对象所依据的规则。
自动存储持续时间——对象在其定义时被放置在内存中,并在程序执行的上下文离开对象的范围时被释放。
静态存储持续时间定义了将在程序开始时放置在内存中并在程序终止时释放的资源。
使用线程存储持续时间创建的对象将彼此分开放置在每个线程的内存中。这在我们创建线程安全的应用程序时很有用。
最后,动态存储时长。定义放置在动态内存中的资源。编译器和静态分析器最困难的情况。这样的对象不会被自动销毁。具有动态存储持续时间的资源通过指针进行管理。借助具有自己的存储期限的控制对象可以方便地控制此类资源,这些对象有义务按时释放它们(RAII习惯用法)。
所有符号都保存在表中特殊部分的目标文件中。现在是对象文件的时候了。
目标文件
如上所述,编译器将翻译单元转换为以特殊方式组织的二进制目标文件。不同的平台有不同的目标文件格式。让我们看看最常见的结构。
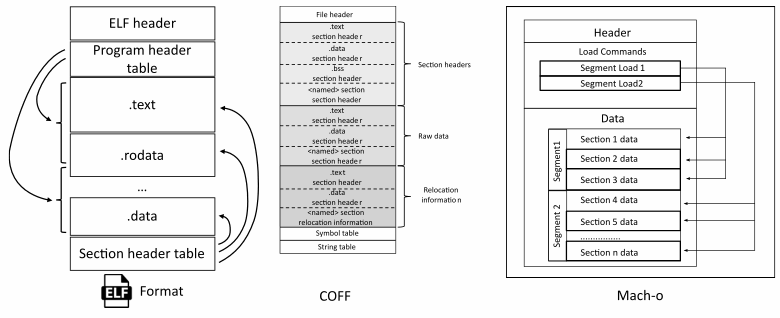
COFF最初用于 UNIX 系统(.o, .obj)并且不支持 64 位架构(因为它们当时不存在)。后来它被ELF格式取代。随着 COFF 的发展,出现了 Portable Executable (PE)。这种格式仍在 Windows 中使用(.exe、.dll)。
Mach-o是 macOS 上的一种对象文件格式。它在结构上与 COFF 不同,但执行相同的功能。这种格式支持不同架构的代码存储。例如,单个可执行文件可以存储 ARM 和 x86 处理器的代码。
ELF是 Unix 系统上的一种目标文件格式。一个小剧透:在为 PVS-Studio 创建对象语义模块时,我们受到了 ELF 的启发。
所有这三种格式都有相似的结构,所以我们将检查在它们中使用的划分为部分的一般概念。让我们以 ELF 为例。请注意,它旨在存储可执行程序代码。由于我们根据静态分析对其进行检查,因此并非所有组件都对我们感兴趣。
ELF Header:
Magic: 7f 45 4c 46 02 01 01 00 00 00 00 00 00 00 00 00
Class: ELF64
Data: 2's complement, little endian
Version: 1 (current)
OS/ABI: UNIX - System V
ABI Version: 0
Type: REL (Relocatable file)
Machine: Advanced Micro Devices X86-64
Version: 0x1
Entry point address: 0x0
Start of program headers: 0 (bytes into file)
Start of section headers: 688 (bytes into file)
Flags: 0x0
Size of this header: 64 (bytes)
Size of program headers: 0 (bytes)
Number of program headers: 0
Size of section headers: 64 (bytes)
Number of section headers: 12
Section header string table index: 1
There are 12 section headers, starting at offset 0x2b0:标题部分包含定义文件格式的信息:Magic、Class、Data、Version 等。此外,它还包含有关生成文件的平台的信息。
接下来的内容是标题和程序部分的列表。
Section Headers:
[Nr] Name Type Off Size ES Flg Lk Inf Al
[ 0] NULL 000000 000000 00 0 0 0
[ 1] .strtab STRTAB 0001b9 0000a3 00 0 0 1
[ 2] .text PROGBITS 000040 000016 00 AX 0 0 16
[ 3] .rela.text RELA 000188 000018 18 11 2 8
[ 4] .data PROGBITS 000058 000005 00 WA 0 0 4
[ 5] .bss NOBITS 00005d 000001 00 WA 0 0 1
[ 6] .comment PROGBITS 00005d 00002e 01 MS 0 0 1
[ 7] .note.GNU-stack PROGBITS 00008b 000000 00 0 0 1
[ 8] .eh_frame X86_64_UNWIND 000090 000038 00 A 0 0 8
[ 9] .rela.eh_frame RELA 0001a0 000018 18 11 8 8
[10] .llvm_addrsig LLVM_ADDRSIG 0001b8 000001 00 E 11 0 1
[11] .symtab SYMTAB 0000c8 0000c0 18 1 6 8有很多部分。有关详细信息,请参阅ELF 文档。例如,让我们看一下其中的一些:
- strtab – 大部分字符串与符号表中的条目相关联(参见符号字符串表);
- 文本——包含可执行程序指令;
- data – 包含程序启动时将加载的所有初始化数据;
- bss – 也存储程序数据,但与“.data”部分不同,数据没有初始化;
- symtab — 程序符号表。
现在,让我们看看这些部分的内容。由于我们是从模块间分析的角度检查主题区域,因此我们将重点关注符号表。
Symbol table '.symtab' contains 8 entries:
Num: Value Size Type Bind Vis Ndx Name
0: 0000000000000000 0 NOTYPE LOCAL DEFAULT UND
1: 0000000000000000 0 FILE LOCAL DEFAULT ABS sym.cpp
2: 0000000000000004 1 OBJECT LOCAL DEFAULT 4 foo(int)::x
3: 0000000000000000 1 OBJECT LOCAL DEFAULT 5 foo(int)::dog
4: 0000000000000000 4 OBJECT LOCAL DEFAULT 4 foo(int)::symbol
5: 0000000000000000 0 SECTION LOCAL DEFAULT 2 .text
6: 0000000000000000 22 FUNC GLOBAL DEFAULT 2 foo(int)
7: 0000000000000000 0 NOTYPE GLOBAL DEFAULT UND Cat::x它由具有特定结构的记录组成。这是最简单的数据库,方便多次读取。此外,所有数据都在内存中对齐。多亏了这一点,我们可以简单地将它们加载到结构中以进一步使用它们。
一些编译器使用他们自己的目标文件格式来存储中间信息。其中包括 LLVM 位码 ( .bc ),它以二进制格式存储 LLVM IR 的中间表示,或 GCC Gimple ( .wpo )。编译器使用所有这些信息来实现链接时间优化,其中还涉及模块间分析。
编译器中的模块间分析
让我们靠近文章的主题。在尝试实现任何东西之前,让我们看看其他工具是如何解决类似任务的。编译器执行大量代码优化。这些包括死代码消除、循环展开、尾递归消除、常量评估等。
例如,您可以在此处阅读GCC的可用优化列表。我敢肯定,您只需几分钟即可浏览此文档。但是,所有转换都在特定的翻译单元内执行。正因为如此,一些有用的信息丢失了,结果优化的有效性也丢失了。模块间分析旨在解决这个问题。它在编译器中成功用于链接时间优化。我们已经在上一篇文章中简要描述了它的工作原理。
第一个编译器(我最喜欢的)——Clang。它属于使用LLVM进行代码生成的编译器组。这种编译器具有模块化架构。其方案如图所示:
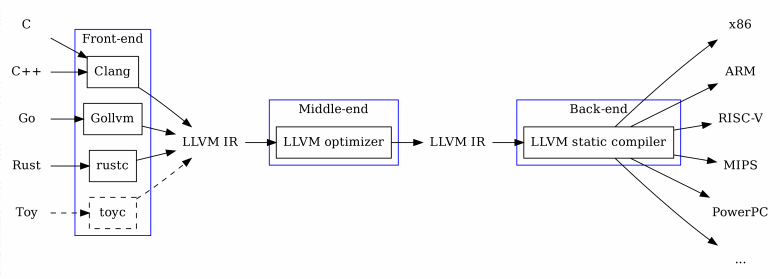
它包含三个部分:
- 前端。将特定语言(在 Clang 中为 C、C++ 和 Objective-C)的代码翻译成中间表示。在这个阶段,我们已经可以执行许多特定于语言的优化;
- 中端。以下是分析或修改中间表示的实用程序。在 LLVM 中,它被表示为一个抽象的汇编器。对其进行优化要方便得多,因为它的功能集被限制在最低限度。还记得 C++ 中有多少种初始化变量的方法吗?LLVM 中间表示中没有(通常意义上的)。所有值都以虚拟寄存器的形式存储在堆栈内存中。这些寄存器通过一组有限的命令(加载/存储、算术运算、函数调用)进行处理;
- 后端。为特定架构生成可执行模块。
这样的架构有很多优点。如果您需要创建自己的适用于大多数架构的编译器,您只需为 LLVM 编写前端即可。此外,开箱即用,您将进行一般优化,例如死代码消除,循环展开等。如果您正在开发新架构,那么为了支持大量流行的编译器,您可以只实现LLVM 的后端。
链接时间优化在中间表示级别工作。让我们看一个人类可读形式的示例:

您可以使用特殊命令将simple.cpp源代码文件转换为中间形式。为了结果简洁起见,在图片中我还应用了大部分优化,删除了所有不必要的代码。我们正在讨论将中间表示的原始版本转换为SSA 形式。如果可能,将删除其中的任何变量分配并替换虚拟寄存器的初始化。当然,经过任何转换后,与 C 或 C++ 源代码的直接联系就会丢失。但是,对链接器重要的外部符号将保留。在我们的示例中,这是add函数。
然而,我们没有抓住重点。让我们回到链接时间优化。LLVM 文档描述了4 个步骤。
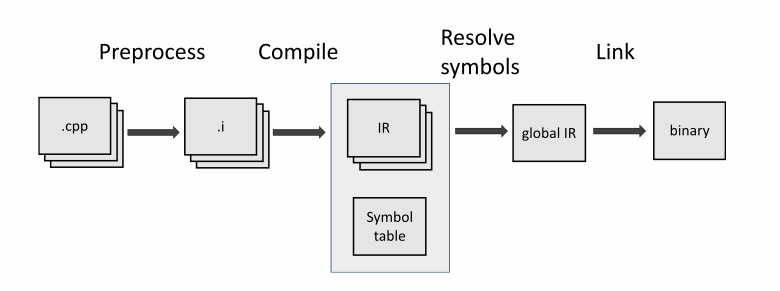
- 读取带有目标代码或中间表示的文件。链接器以随机顺序读取目标文件并将信息收集到全局符号表中。
- 符号分辨率。链接器查找没有定义的符号,替换弱符号,记住“活动符号”等。它不需要知道具有中间表示的源文件的确切内容。在这个阶段,重要的是程序不违反单一定义规则。
- 优化具有中间表示的文件。对于每个目标文件,链接器都提供了它们需要的符号。之后,优化器根据收集到的信息执行等效转换。例如,在这个阶段,根据整个程序中的数据流分析,将程序中未使用的函数或无法访问的代码删除。此步骤的结果是包含来自所有翻译单元的数据的合并目标文件。要准确了解 LLVM 如何通过模块,我们需要研究它的源代码。然而,这篇文章不是关于那个。
- 优化后的符号分辨率。Wen需要更新符号表。在这个阶段,与在第三阶段删除的符号相关联的符号被检测到并且也被删除。链接器继续照常工作。
我们不能忘记GCC — 一组用于 C、C++、Objective-C、Fortran、Ada、Go 和 D 的编译器。它还具有链接时间优化。但是,它们的排列方式略有不同。
在翻译过程中,GCC 也会生成它的中间表示——GIMPLE。然而,与 LLVM 不同的是,GIMPLE 不作为单独的文件存储,而是在特殊部分中的目标代码旁边。此外,它更类似于程序的源代码,尽管它是一种具有自己语法的独立语言。查看文档中的示例。
为了存储 GIMPLE,GCC 使用 ELF 格式。默认情况下,它们只包含程序的字节码。但是如果我们指定-ffat-lto-objects标志,那么 GCC 会将中间代码放在完成的目标代码旁边的单独部分中。
在 LTO 模式下,GCC 生成的目标文件只包含 GIMPLE 字节码。此类文件称为slim文件,其设计目的是使ar和nm等实用程序能够理解 LTO 部分。
通常,LTO 到 GCC分两个阶段执行。
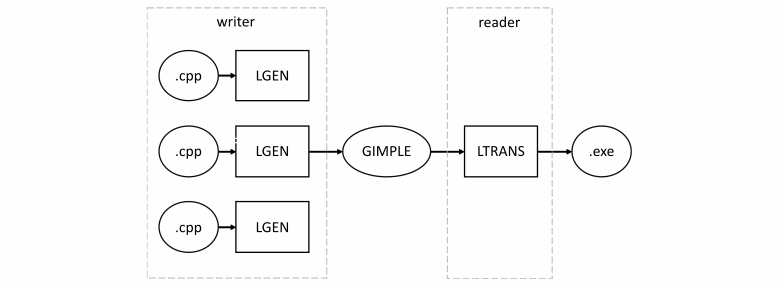
- 第一阶段是作家。GCC 创建代码优化所需的所有内部数据结构的流式表示。这包括有关符号、类型和函数体的中间 GIMPLE 表示的信息。这个过程称为 LGEN。
- 第二阶段是读者。GCC 使用已经写入其中的模块间信息第二次通过目标模块,并将它们合并到一个翻译单元中。此步骤称为 LTRANS。然后对完成的目标文件进行优化。
这种方法适用于小程序。然而,由于所有翻译单元与中间信息一起链接成一个,因此在一个线程中执行进一步的优化。此外,我们必须将整个程序加载到内存中(不仅仅是全局符号表),这可能是个问题。
因此,GCC 支持一种称为 WHOPR 的模式,在该模式中,目标文件由片段链接。链接基于调用图。这允许我们并行执行第二阶段,而不是将整个程序加载到内存中。
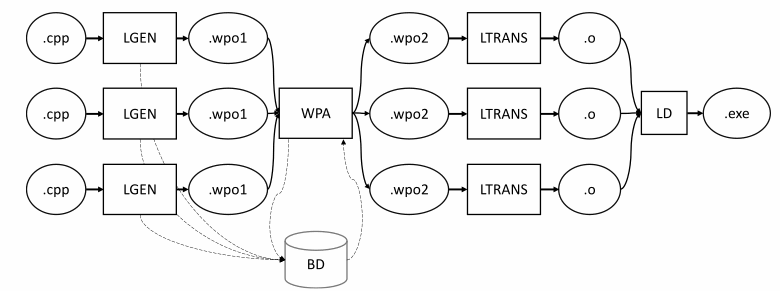
- 在 LGEN 阶段,以与正常模式相同的方式生成一组具有 GIMPLE ( wpo1 )中间表示的文件。
- 此外,在WPA阶段,基于对函数调用(Call Site)的分析,将接收到的文件分组为一组组合文件(wpo2)。
- 在 LTRANS 阶段,对每个.wpo2文件执行本地转换,然后链接器将它们合并为可执行文件。
通过这种实现,我们可以在并行线程中运行 LTO(WPA 阶段除外)。我们不必将大文件加载到 RAM 中。
结论
本文这部分的很多内容只是从作者的角度提供的背景信息。如开头所述,作者不是该主题的专家。这就是为什么他似乎对理解伟人编写的机制的特殊性很感兴趣。它们中的大多数都隐藏在简化开发的工具后面。这当然是正确的。但是,了解我们每天使用的机器的幕后情况是很有用的。如果这篇文章很有趣,欢迎来到第二部分,我们将在检查上述解决方案后应用我们获得的信息。


")
![21 个最佳 Javascript IDE 和代码编辑器 [CSS、HTML、JavaScript]](https://www.code8cn.com/wp-content/uploads/2022/10/image-219-150x150.png "21 个最佳 Javascript IDE 和代码编辑器 [CSS、HTML、JavaScript]")

")