在第 1 部分中,我们讨论了 C 和 C++ 项目编译的基础知识。我们还讨论了链接和优化。在第 2 部分中,我们将深入研究模块间分析并讨论其另一个目的。但这次我们不会讨论源代码优化——我们将通过 PVS-Studio 的示例来了解如何提高静态分析的质量。
静态分析
大多数静态分析器(包括 PVS-Studio)的工作方式类似于编译器前端的工作方式。为了解析代码,开发人员构建了一个类似的模型并使用相同的遍历算法。因此,在本文的这一部分,您将学习到许多与编译理论相关的术语。我们在第 1 部分中讨论了其中的许多内容——如果您还没有的话,一定要看看!
很久以前,我们的开发人员已经在 C# 分析器中实现了模块间分析。由于 Roslyn 平台提供的基础设施,这成为可能。
但是当我们刚开始为 C 和 C++ 实现模块间分析时,我们遇到了许多问题。现在我想分享一些我们使用的解决方案——希望你会发现它们有用。
第一个问题是分析仪的架构——我们的分析仪显然还没有准备好进行模块间分析。让我解释一下为什么。看看下面的方案:
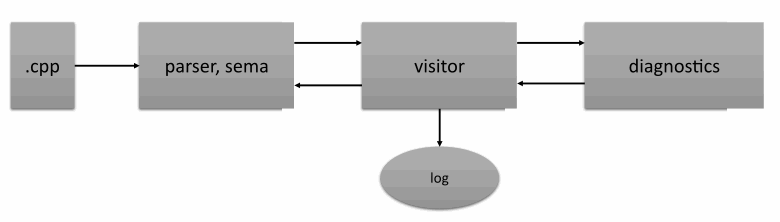
分析器执行程序文本的语法和语义分析,然后应用诊断规则。翻译和语义分析——尤其是数据流分析——一次性完成。这种方法可以节省内存并且效果很好。
一切都很好,直到我们需要位于代码中更远的信息。为了继续分析,开发人员必须提前收集分析工件并在翻译后对其进行处理。不幸的是,这增加了内存开销并使算法复杂化。原因是我们的遗留代码。我们必须维护它并使其适应静态分析的需要。但我们希望在未来改进这一点,而不是一次性执行分析。尽管如此,在我们面临实现模块间分析的任务之前,我们的遗留代码并没有引起重大问题。
让我们以下图为例:
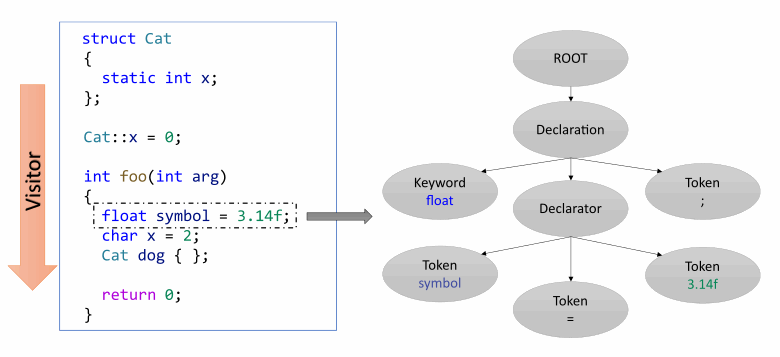
假设分析器为翻译后的函数foo构建了一个内部表示。根据指令为它依次构建解析树。当分析器离开翻译单元的上下文时,这棵树将被销毁。如果我们需要再次检查翻译单元的主体,我们将不得不再次翻译它以及其中的所有符号。但是,这在性能上不是很有效。此外,如果开发人员使用模块间分析模式,他们可能需要重新翻译不同文件中的大量函数。
第一个解决方案是将代码解析的中间结果保存到文件中——以便以后可以重用。使用这种方法,我们不必多次翻译相同的代码。它更方便,更节省时间。但是这里有一个问题。分析仪内存中程序代码的内部表示可能与源代码不同。可以删除或修改一些对分析无关紧要的片段。因此,不可能将表示链接到源文件。此外,保存仅存储在收集它们的块的上下文中的语义分析数据(数据流、符号执行等)存在困难。编译器通常将程序的源代码转换为与语言上下文隔离的中间表示(这正是GCC和Clang可以)。这种语言上下文通常可以表示为具有自己语法的单独语言。
这是一个很好的解决方案。对这种表示进行语义分析更容易,因为它的内存操作集非常有限。例如,在 LLVM IR 中读取或写入堆栈内存时会立即清除。这在加载/存储指令的帮助下发生。然而,在我们的案例中,我们必须对分析器的架构进行重大更改以实现中间表示。这将花费我们没有的太多时间。
第二种解决方案是对所有文件运行语义分析(不应用诊断规则)并提前收集信息。然后以某种格式保存它,以便稍后在第二个分析器通过时使用。这种方法需要进一步开发分析仪的架构。但至少它会花费更少的时间。此外,这种方法有其优点:
- 通过次数调节分析深度。因此,我们不必跟踪无限循环。我们将在后面更详细地讨论这个问题。让我注意到,在撰写本文时,我们将自己限制在一次分析过程中;
- 分析很好地并行化,因为在第一个分析器通过期间我们没有单个数据;
- 可以提前为第三方库准备一个带有语义信息的模块(如果有源代码的话),一起上传。我们还没有实现这一点,但我们计划在未来这样做。
通过这样的实现,我们需要以某种方式保存有关符号的信息。现在你明白为什么我在文章的第一部分谈论了这么多。事实上,我们必须编写链接器。而不是合并目标代码,它应该合并语义分析的结果。尽管链接器的工作比编译器的工作更容易,但链接器使用的算法对我们来说还是很方便的。
语义分析
现在让我们继续进行语义分析。分析程序的源代码时,分析器会收集有关类型和符号的信息。
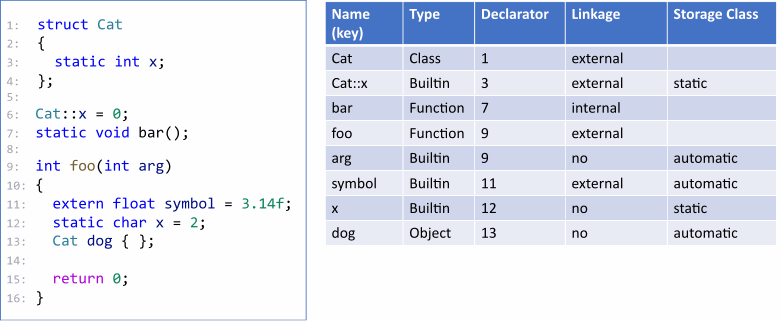
除了公共信息外,还收集了所有声明的位置。这些事实必须存储在模块之间,以便稍后在诊断规则中显示消息。同时进行符号执行和数据流分析。结果被记录为与符号相关的事实。让我们以下图为例:
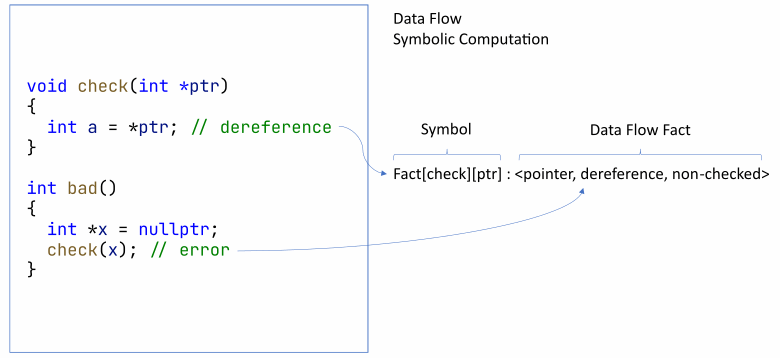
在检查函数中,指针被取消引用。但是这个指针没有被检查。分析仪可以记住这一点。然后,坏函数接收未经检查的nullptr。此时,分析器肯定可以发出关于空指针取消引用的警告。
我们决定同时实现过程间和模块间分析,因为这有助于将符号与语义事实一起存储——分析器在审查代码时得出的一组结论。
数据流对象
现在我们越来越接近最有趣的部分了。这里是!数据流对象 ( .dfo ) — 我们用于表示二进制语义分析数据的格式。
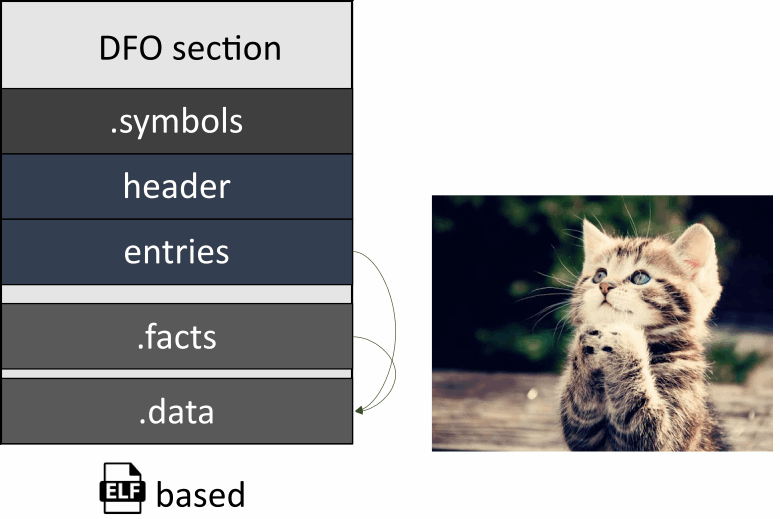
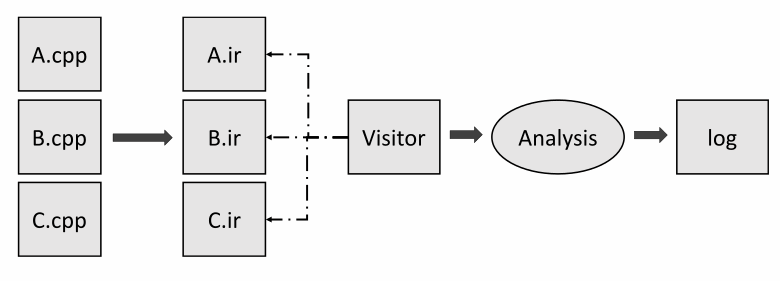
我们的任务是在每个翻译单元中存储有关符号和数据的信息。假设它以特殊格式存储在相应的文件中。但是,为了以后使用这些信息,我们需要将它们合并到一个文件中,以便在运行分析器的过程中进一步加载它。
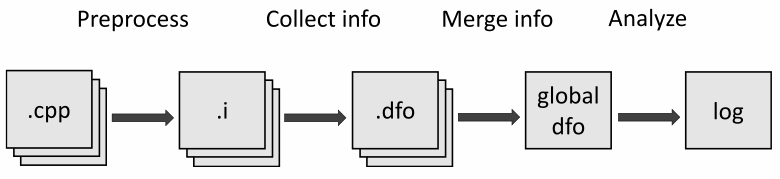
看起来像一个链接器,你不这么认为吗?这就是我们不想重新发明轮子的原因——我们只是创建了类似于 ELF 的 DFO 格式。让我们仔细看看它。
该文件分为几个部分:DFO 部分、.symbol、.facts和.data。
DFO 部分包含其他信息:
- Magic — 格式标识符;
- Version——名字暗示了它的用途;
- Section offset——节开始的地址;
- Flags — 附加标志。尚未使用;
- Section count — 节数。
接下来是带有符号的部分。
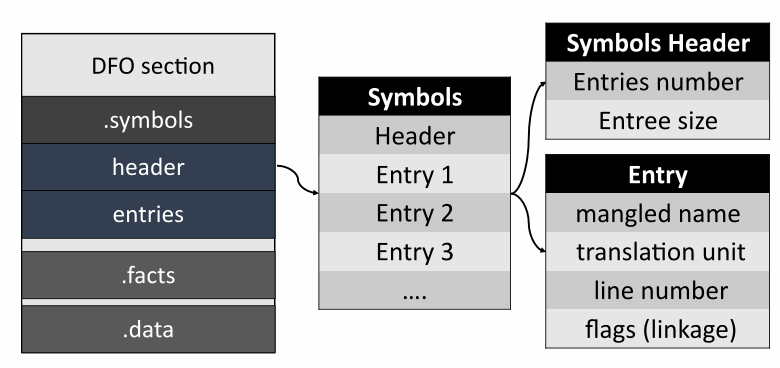
标题包含有关表中记录数的信息。每条记录都包含一个错位名称、符号在源代码文件中的位置、有关链接的信息以及存储持续时间。
最后是事实部分。
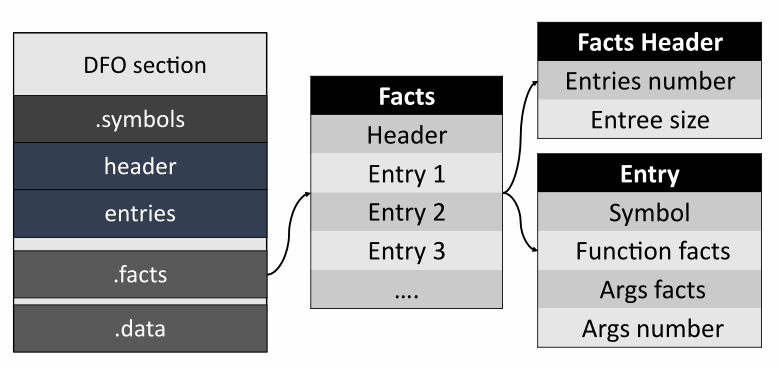
就像符号一样,标题包含有关条目数量的信息。这些条目包括对符号的引用以及它们的各种事实。事实被编码为一个固定长度的元组——这使得它们更容易读写。在撰写本文时,事实仅针对函数及其参数保存。我们尚未保存有关分析器为返回的函数值执行的符号执行的信息。
数据部分包含文件中其他条目引用的字符串。这允许创建数据实习机制以节省内存。此外,所有记录都完全对齐,因为它们以结构形式存储在内存中。对齐是在以下公式的帮助下计算的:
additionalBytes = (align - data.size() % align) % align假设我们已经在文件中有数据——它的写法如下:

然后我们想在那里插入一个int类型的整数。
Align(x) = alignof(decltype(x)) = 4 bytes
Size(x) = sizeof(x) = 4 bytes
data.size = 3 bytes
additionalBytes = (align - data.size() % align) % align =
= (4 - 3 % 4) % 4 = 1 byte;我们得到 1 个字节的移位。现在我们可以插入整数。

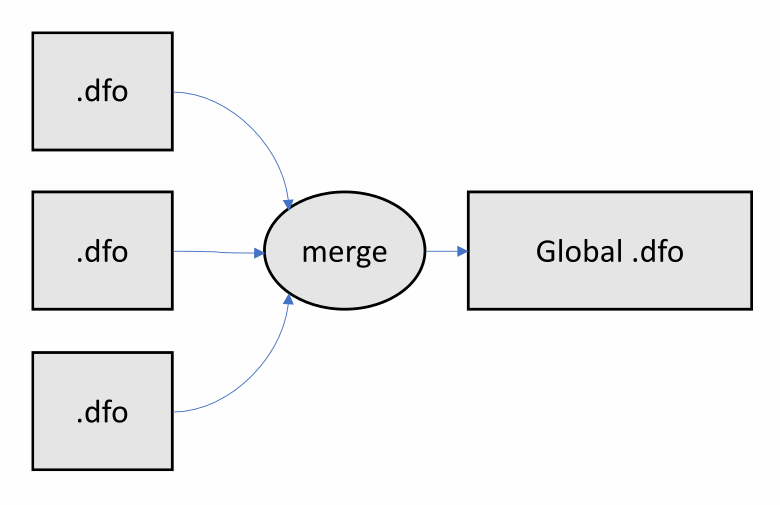
现在让我们仔细看看将.dfo文件合并为一个文件的阶段。分析器按顺序从每个文件中加载信息并将其收集到一个表中。此外,分析器以及链接器必须解决具有相同名称和签名的符号之间的冲突。在示意图中,如下所示:
但是,有几个陷阱。
前段时间,我的同事写了一篇文章《Linux 内核 30 岁:来自 PVS-Studio 的祝贺》。相当有趣的一个!当你有时间的时候读一读。在我的队友开始分析 Linux 内核后,他得到了一个 30 GB 的共享.dfo文件!所以,我们试图找出原因并发现了一个错误。至此,我们已经知道如何确定符号链接的类别了。但是,我们仍然将它们全部写入一个通用的.dfo文件。我们这样做是为了在定义这些符号的特定翻译单元中使分析更加精确。让我们看一下图片:
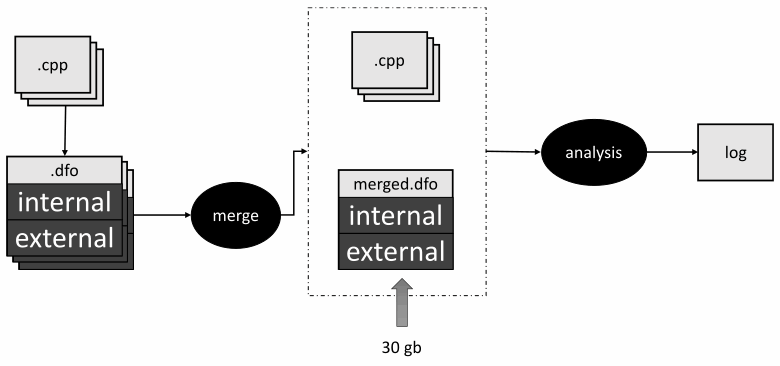
正如我之前提到的,. 为每个翻译单元生成dfo文件。然后,它们被合并到一个文件中。之后,PVS-Studio 仅使用此文件和源文件进行进一步分析。
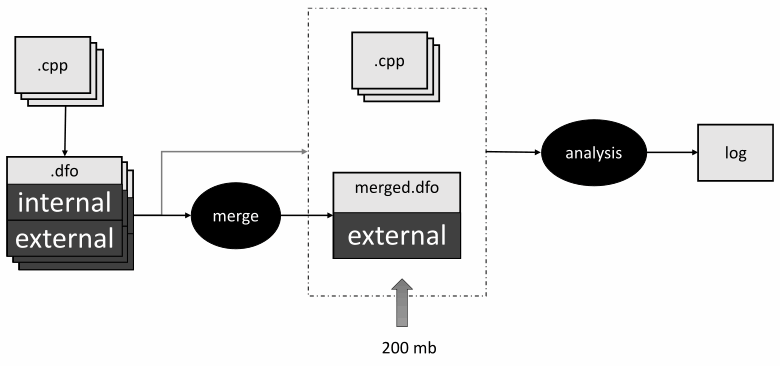
但是当我们检查 Linux 内核时,我们发现内部链接的符号比外部链接的符号多。这导致了如此大的.dfo文件。解决方案很明显。我们只需要在合并阶段将符号与外部链接结合起来。在第二个分析器的过程中,我们依次上传了 2 个.dfo文件——合并后的文件和第一阶段后得到的文件。这使我们能够将所有符号与整个项目分析后获得的外部链接合并,并将符号与特定翻译单元的内部链接合并。因此,文件大小不超过 200 MB。
但是,如果有 2 个具有相同名称和签名的符号并且其中一个具有外部链接,该怎么办?这绝对是违反 ODR 的。编译的程序包含这样的东西不是一个好主意。如果分析器开始检查实际上没有合并的文件,我们可能会在符号之间发生冲突。例如,CMake 生成一个常见的compile_commands.json整个项目的文件,而不考虑链接器的命令。稍后我们将详细讨论这一点。幸运的是,即使违反了 ODR,我们仍然可以继续分析(前提是符号的语义信息匹配)。在这种情况下,您可以简单地选择一个符号。如果信息不匹配,我们将不得不从表中删除所有具有此签名的符号。然后分析器会丢失一些信息——但是,它仍然能够继续分析。例如,当同一文件多次包含在分析中时,可能会发生这种情况,前提是其内容根据编译标志而变化(例如,在#ifdef的帮助下)。
深度分析
我想指出,在撰写本文时,该功能尚未实现。但我想分享一个关于如何做到这一点的想法。我们可能会将它包含在未来的分析器版本中——除非我们想出更好的主意。
我们专注于我们可以将信息从一个文件传输到另一个文件这一事实。但是如果数据链更长呢?让我们考虑一个例子:

空指针通过main -> f1 -> f2传递。分析器可以记住f1接收到一个指针,并且该指针在f2中被取消引用。但是分析器不会注意到f2接收到空指针。要注意到这一点,分析器首先需要对main和f1函数运行模块间分析,以了解ptr指针为空。然后分析仪应再次检查f1和f2功能。但这不会发生在当前的实现中。我们来看看下面的方案:
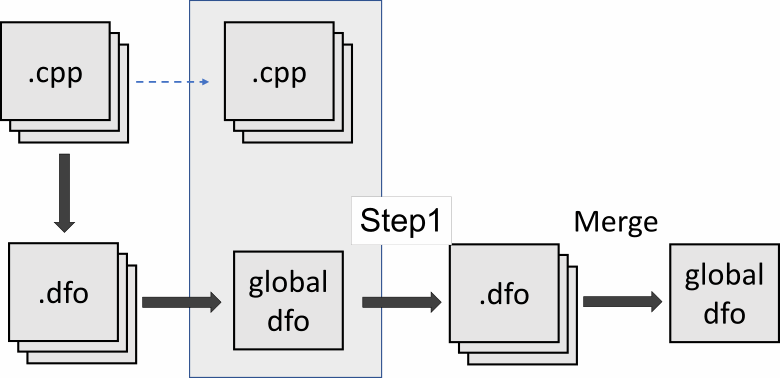
如您所见,在合并阶段之后,分析仪不再能够继续进行模块间分析。好吧,老实说,这是我们方法中的一个缺陷。如果我们单独重新分析我们需要的文件,我们可以解决这种情况。然后我们应该合并现有的摘要.dfo文件和新信息:
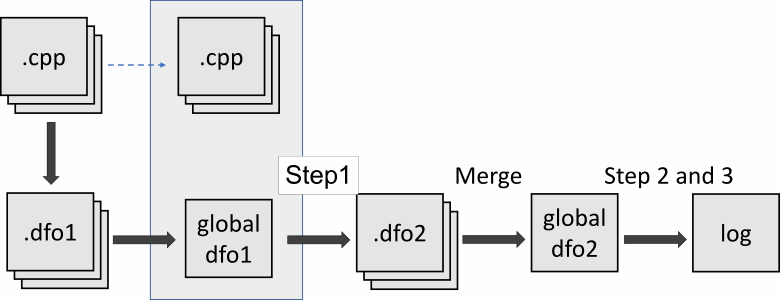
但是如何找出我们应该再次分析哪些翻译单元呢?分析来自函数的外部调用会有所帮助。为此,我们需要构建一个调用图。除了我们没有。我们希望将来创建一个调用图,但在撰写本文时,还没有这样的功能。此外,通常,一个程序包含相当多的外部调用。我们不能确定这是否有效。我们唯一能做的就是重新分析所有的翻译单元,重写事实。每次通过将分析深度增加 1 个函数。是的,需要一段时间。但我们可以在周末每周至少这样做一次。总比没有好。如果我们将来创建中间表示,我们将解决这个问题。
所以,现在我们完成了对模块间分析的内部部分的讨论。不过,与界面部分相关的还有几个发人深省的地方。所以,让我们从分析器核心转向运行它的工具。
增量分析
想象一下下面的情况。您正在开发一个已经被静态分析器检查过的项目。而且您不希望每次更改某些文件时都运行完整分析。我们的分析器提供了一个功能(类似于编译),它只对修改后的文件运行分析。那么,是否可以对模块间分析做同样的事情呢?不幸的是,事情并没有那么简单。最简单的方法是从修改过的文件中收集信息并将其与通用文件结合起来。下一步是对修改后的文件和公共文件一起运行分析。当分析深度等于一个函数时,这将起作用。但是我们会丢失其他文件中可能由新更改引起的错误。因此,我们这里唯一可以优化的就是语义数据收集阶段。让’
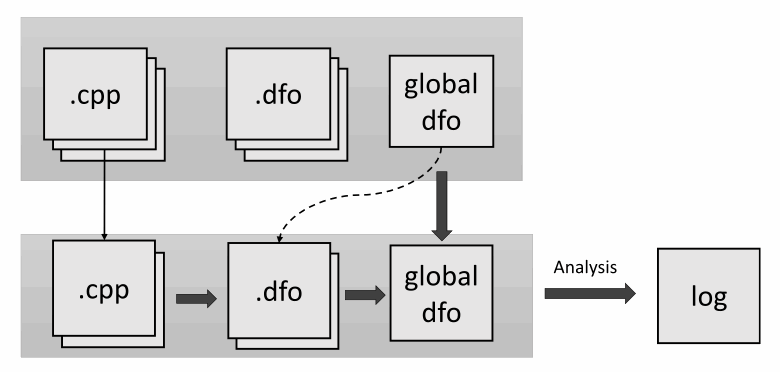
第一行显示整个项目的状态。第二行说明已更改的文件。在那之后:
- 为修改后的源文件生成.dfo文件;
- 接收到的文件与单个文件合并;
- 对所有项目文件进行全面分析。
分析有几个部分的项目
大多数情况下,具有程序源代码的项目由几个部分组成。此外,每个都可以有自己的一组符号。经常会发生同一个文件与其中几个文件合并的情况。在这种情况下,开发人员负责将正确的参数传递给链接器。现代构建系统使这个过程相对方便。但是有很多这样的系统,并不是所有的系统都允许你跟踪编译命令。
PVS-Studio 支持 2 种 C 和 C++ 项目格式 — Visual Studio (.vcxproj)和JSON 编译数据库。我们对Visual Studio (.vcxproj)没有问题。这种格式提供了确定项目组件的所有必要信息。但是 JSON 编译数据库格式有点复杂……
JSON 编译数据库格式(又名compile_commands.json)旨在用于代码分析工具,例如 clangd。到目前为止,我们没有遇到任何问题。但是,有一个细微差别——其中的所有编译命令都写在一个平面结构中(在一个列表中)。而且,不幸的是,这些命令不包括链接器的命令。如果一个文件在项目的多个部分中使用,它的命令将一个接一个地编写,没有任何附加信息。让我们用一个例子来说明这一点。要生成compile_commands.json,我们将使用 CMake。假设我们有一个共同的项目,以及它的 2 个组件:
// CMakeLists.txt
....
project(multilib)
....
add_library(lib1 A.cpp B.cpp)
add_library(lib2 B.cpp)
> cmake -DCMAKE_EXPORT_COMPILE_COMMADS=On /path/to/source-root
// compile_commands.json
[
{
"file": "....\\A.cpp",
"command": "clang-cl.exe ....\\A.cpp -m64 .... -MDd -std:c++latest",
"directory": "...\\projectDir"
},
{
"file": "....\\B.cpp",
"command": "clang-cl.exe ....\\B.cpp -m64 .... -MDd -std:c++latest",
"directory": "...\\projectDir "
},
{
"file": "....\\B.cpp",
"command": "clang-cl.exe ....\\B.cpp -m64 .... -MDd -std:c++latest",
"directory": "....\\projectDir "
}
]如您所见,当我们编译整个项目时,生成的compile_commands.json包含B.cpp的命令。并且此命令重复两次。在这种情况下,分析器将加载其中一个命令的符号,因为它们是相同的。但是,如果我们使B.cpp文件的内容依赖于编译标志(例如,借助预处理器指令),则不会有这样的保证。在写这篇文章的时候,这个问题还没有得到妥善解决。我们计划这样做,但就目前而言,我们必须使用我们所拥有的。
或者,我发现了通过 CMake管理compile_commands.json内容的可能性。但是,这种方法不是很灵活。我们必须手动修改CMakeLists.txt 。在 CMake 3.20 和更新版本中,可以为目标指定EXPORT_COMPILE_COMMANDS属性。如果设置为TRUE,命令将被写入目标的最终文件。因此,在CMakeLists.txt中添加几行,我们可以生成必要的命令集:
CMakeLists.txt:
....
project(multilib)
....
set(CMAKE_EXPORT_COMPILE_COMMANDS FALSE) #disable generation for all targets
add_library(lib1 A.cpp B.cpp)
add_library(lib2 B.cpp)
#enable generatrion for lib2
set_property(TARGET lib2 PROPERTY EXPORT_COMPILE_COMMANDS TRUE)然后,我们在compile_commands.json上运行分析:
pvs-studio-analyzer analyze -f /path/to/build/compile_commands.json ....请注意,如果我们同时为多个构建目标设置此属性,它们的编译命令也会合并到一个列表中。
PVS-Studio 提供了一种在编译数据库的帮助下直接通过 CMake 运行分析的方法。为此,您需要使用特殊的 CMake 模块。您可以在文档中了解更多信息。在撰写本文时,我们还没有实现对模块间分析的支持。不过,这个方向还是很有希望的。
另一种选择是跟踪链接器命令,就像我们在CLMonitor实用程序的帮助下或通过strace对编译命令所做的那样。我们将来可能会这样做。但是,这种方法也有一个缺点——要跟踪所有调用,需要构建项目。
连接第三方库的语义模块
想象一下下面的情况。您有一个需要分析的主要项目。预编译的第三方库连接到项目。模块间分析会与他们一起工作吗?不幸的是,答案是“不”。如果您的项目没有第三方库的编译命令,语义分析将不会在它们上运行,因为只能访问头文件。但是,理论上有可能提前为图书馆准备一个语义信息模块并将其连接到分析中。为此,我们应该将此文件与项目的主文件合并。在撰写本文时,这只能手动完成。但是,我们希望在未来自动化这个过程。这是主要思想:
- 我们需要提前为第三方库准备一个合并的.dfo文件,通过分析其代码。
- 执行模块间分析的第一阶段,并为主要项目的每个翻译单元准备.dfo文件。
- 将项目的所有语义模块与第三方库文件合并。如果这不违反 ODR,一切都会顺利进行。
- 执行模块间分析的第三阶段。
同时,我们必须牢记 . dfo文件以绝对格式存储。因此,我们不能移动第三方库的源或将文件传递给其他机器。我们仍然需要想出一种方便的方式来配置第三方语义模块。
优化
好吧,我们弄清楚了有关分析算法的一切。现在,我想讨论两个我们认为有趣的优化。
字符串实习
这里我的意思是在单一来源中缓存数据,以便可以从任何地方引用它。大多数情况下,这种优化是针对字符串实现的。顺便说一句,我们的文件包含相当多的字符串。因为符号和事实的每个位置都作为字符串存储在 DFO 文件中。以下是它的外观示例:
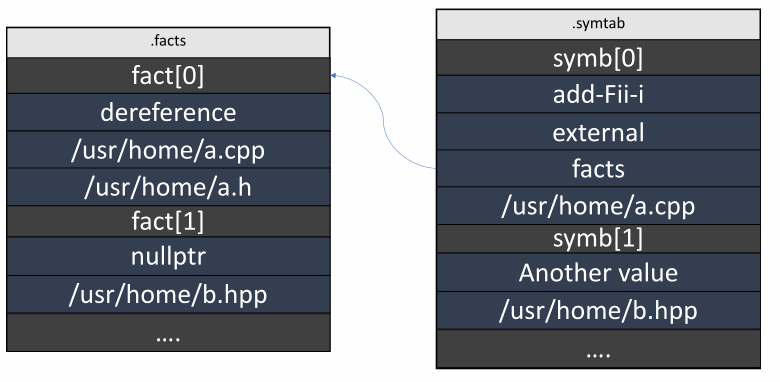
正如我们所看到的,数据经常是重复的。如果我们将所有唯一的字符串添加到.data部分,文件大小将显着减小,以及读取和写入文件数据的时间。在关联容器的帮助下实现这样的算法非常简单:
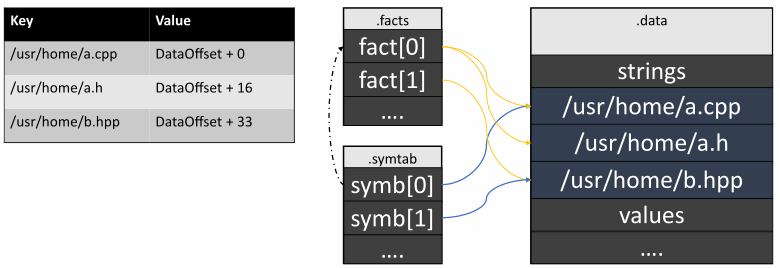
现在,除了数据部分之外的所有部分都只包含相应的字符串地址。
前缀树
尽管字符串现在是唯一的,但其中的数据仍然是重复的。例如,在下图中,所有路径都具有相同的第一部分或前缀:

这种情况经常重复。然而,trie 解决了这个问题。
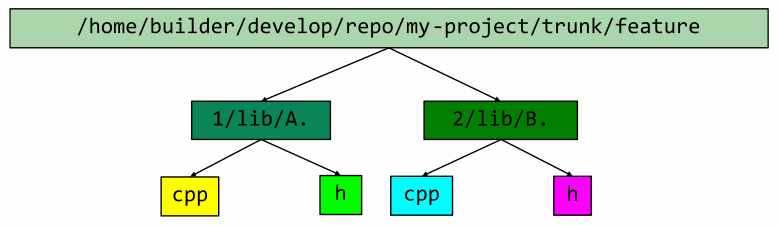
在这种视图中,末端节点(叶子)将是引用。我们不应该出现一个字符串与另一个字符串的前缀完全重合的情况。这不应该发生,因为我们使用系统中唯一的文件。我们可以通过将完整的字符串传递回树的根来恢复它。这种 trie 中的搜索操作与我们搜索的字符串的长度成正比。在不区分大小写的文件系统中可能存在问题。两个不同的路径可能指向同一个文件,但在我们的例子中,这可以忽略不计,因为这是稍后在比较过程中处理的。然而,在 . dfo文件,我们仍然可以存储已经规范化的原始路径。
结论
模块间分析提供了许多以前无法访问的可能性,并有助于发现在常规代码审查期间难以检测到的有趣错误。尽管如此,我们仍然需要做很多事情来优化和扩展功能。您现在可以尝试模块间分析。它在 PVS-Studio v7.14 和更新版本中可用。您可以在我们的网站上下载最新的分析仪版本。想了解更多关于模块间分析的信息?如果您还没有,请阅读上一篇文章。如果您有任何问题或想法,请随时给我们写信,我们一定会尽力提供帮助。请注意,通过提供的链接申请试用时,您可以获得 30 天的企业许可证。我们希望这种模式能帮助您修复项目中的错误。




