如果我们不了解真正发生的事情,Rust 的所有权和借用可能会令人困惑。将先前学习的编程风格应用于新范式时尤其如此。我们称之为范式转变。所有权是一个新奇的想法,但起初很难理解,但我们越努力就越容易。
在深入了解 Rust 的所有权和借用之前,让我们首先了解什么是“内存安全”和“内存泄漏”以及编程语言如何处理它们。
什么是内存安全?
内存安全是指软件应用程序的状态,其中内存指针或引用始终指向有效内存。因为内存损坏是可能的,所以如果程序不是内存安全的,那么它的行为就很难保证。简而言之,如果一个程序不是真正的内存安全,那么它的功能几乎没有保证。在处理内存不安全的程序时,恶意方能够利用该漏洞读取机密或在其他人的机器上执行任意代码。

让我们用一个伪代码来看看什么是有效内存。
// pseudocode #1 - shows valid reference
{ // scope starts here
int x = 5
int y = &x
} // scope ends here
在上面的伪代码中,我们创建了一个 x 赋值为 的变量10。我们使用 & 运算符或关键字来创建引用。因此, &x 语法允许我们创建一个引用 的值的引用 x。简而言之,我们创建了一个 x 拥有 5 的变量和 y 一个引用 x.
由于两个变量 x 和 y 都在同一个块或范围内,因此变量 y 具有引用 的值的有效引用 x。因此,变量 y 的值为 5。
看看下面的伪代码。正如我们所看到的,范围 x 仅限于创建它的块。当我们尝试访问 x 其范围之外时,我们会陷入悬空引用。悬空参考……?它到底是什么?
// pseudocode #2 - shows invalid reference aka dangling reference
{ // scope starts here
int x = 5
} // scope ends here
int y = &x // can't access x from here; creates dangling reference
悬空参考
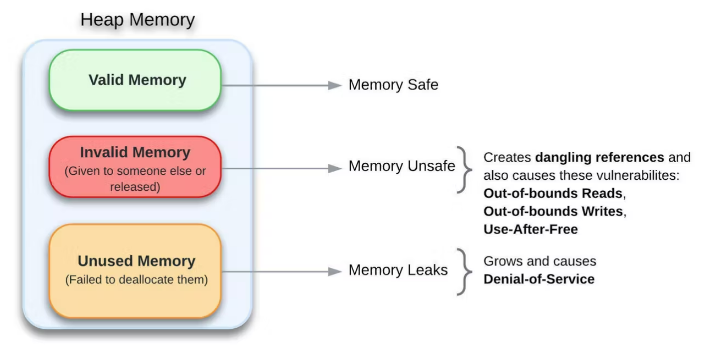
悬空引用是指向已分配给其他人或释放(释放)的内存位置的指针。如果程序(又名 进程)引用已释放或清除的内存,它可能会崩溃或导致不确定的结果。
话虽如此, 内存不安全 是一些编程语言的属性,允许程序员处理无效数据。因此,内存不安全引入了各种可能导致以下主要安全漏洞的问题:
- Out-of-bounds Reads
- Out-of-bounds Writes
- Use-After-Free
- 越界读取
- 越界写入
- 释放后使用
内存不安全导致的漏洞是许多其他严重安全威胁的根源。不幸的是,发现这些漏洞对开发人员来说可能极具挑战性。
什么是内存泄漏?
了解什么是内存泄漏及其后果是很重要的。

内存泄漏是一种 无意的内存消耗形式,开发人员无法在 不再需要 分配的 堆内存块时释放它。这与内存安全正好相反。稍后会详细介绍不同的内存类型,但现在,只需知道 堆栈 存储编译时已知的固定长度变量,而稍后可能在运行时更改的变量大小必须放在 堆上。
与堆内存分配相比,堆栈内存分配被认为更安全,因为当程序员或程序运行时本身不再相关或不需要时,内存会自动释放。
但是,当程序员在堆上生成内存并且在没有垃圾收集器的情况下无法将其删除时(在 C 和 C++ 的情况下),就会发生内存泄漏。此外,如果我们丢失了对一块内存的所有引用而没有释放该内存,那么我们就会发生内存泄漏。我们的程序将继续拥有该内存,但它无法再次使用它。
一点点内存泄漏不是问题,但是如果一个程序分配了大量的内存并且从不释放它,那么程序的内存占用会不断上升,从而导致拒绝服务。
当程序退出时,操作系统会立即恢复它拥有的所有内存。因此,内存泄漏只会在程序运行时影响它。一旦程序终止,它就没有效果。
让我们回顾一下内存泄漏的主要后果。
内存泄漏通过减少可用内存(堆内存)的数量来降低计算机的性能。它最终会导致整个或部分系统停止正常工作或严重减速。崩溃通常与内存泄漏有关。
我们找出如何防止内存泄漏的方法将根据我们使用的编程语言而有所不同。内存泄漏可能从一个很小且几乎“不明显的问题”开始,但它们会迅速升级并压倒它们所影响的系统。在可行的情况下,我们应该留意它们并采取行动纠正它们,而不是任其发展。
内存不安全与内存泄漏
内存泄漏和内存不安全是预防和补救方面最受关注的两类问题。重要的是要注意修复一个并不会自动修复另一个。
各种类型的记忆及其运作方式
在我们继续之前,了解我们的代码将在运行时使用的不同类型的内存非常重要。
有两种类型的存储器,如下所示,这些存储器的结构不同。
- Processor register
- Static
- Stack
- Heap
- 处理器寄存器
- 静止的
- 堆
- 栈
处理器寄存器 和 静态内存类型都 超出了本文的范围。
堆栈内存及其工作原理
堆栈按接收顺序存储数据,并以相反的顺序将其删除。可以按照后进先出 (LIFO)的顺序从堆栈中访问项目 。将数据添加到堆栈中称为“推送”,将数据从堆栈中移除称为“弹出”。
存储在堆栈上的所有数据都必须具有已知的固定大小。编译时大小未知或稍后可能更改的数据必须存储在堆上。
作为开发人员,我们不必担心堆栈内存 分配 和 释放;堆栈内存的分配和释放由编译器“自动完成”。这意味着当堆栈上的数据不再相关(超出范围)时,它会自动删除而无需我们的干预。
这种内存分配也称为 临时内存分配,因为一旦函数完成执行,属于该函数的所有数据都会“自动”从堆栈中清除。
Rust 中的所有原始类型都存在于堆栈中。数字、字符、切片、布尔值、固定大小的数组、包含原语的元组和函数指针等类型都可以放在堆栈上。
堆内存及其工作原理
与栈不同,当我们将数据放到堆上时,我们会请求一定的空间。内存分配器在堆中定位一个足够大的未占用位置,将其标记为正在使用,并返回对该位置地址的引用。这称为 分配。
在堆上分配比压入堆栈要慢,因为分配器永远不必寻找空位置来放置新数据。此外,因为我们必须遵循指针来获取堆上的数据,所以它比访问堆栈上的数据要慢。与在编译时分配和释放的栈不同,堆内存是在程序指令执行期间分配和释放的。
在某些编程语言中,为了分配堆内存,我们使用关键字 new。这个 new 关键字(又名 operator)表示在堆上分配内存的请求。如果堆上有足够的内存可用,则 new 操作符初始化内存并返回新分配的内存的唯一地址。
值得一提的是,堆内存是由程序员或运行时“显式”释放的。
其他各种编程语言如何保证内存安全?
当谈到内存管理,尤其是堆内存时,我们希望我们的编程语言具有以下特征:
- 我们希望在不再需要内存时尽快释放内存,而不需要运行时开销。
- 我们永远不应该维护对已释放数据的引用(也称为悬空引用)。否则,可能会发生崩溃和安全问题。
编程语言通过以下方式以不同的方式确保内存安全:
- 显式内存释放 (由 C、C++ 采用)
- 自动或隐式内存释放 (Java、Python 和 C# 采用)
- 基于区域的内存管理
- 线性或独特类型系统
基于区域的内存管理 和 线性类型系统都 超出了本文的范围。
手动或显式内存释放
当使用显式内存管理时,程序员必须“手动”释放或擦除分配的内存。“释放”运算符(例如, delete 在 C 中)存在于具有显式内存释放的语言中。
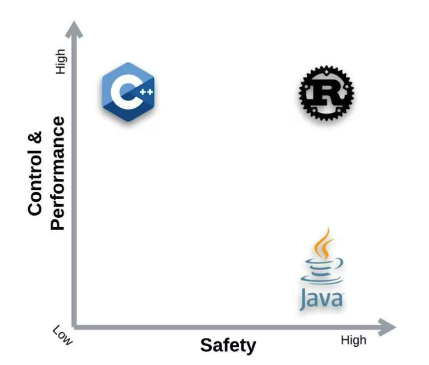
在 C 和 C++ 等系统语言中,垃圾回收成本太高,因此显式内存分配仍然存在。
将释放内存的责任留给程序员有利于程序员完全控制变量的生命周期。但是,如果释放操作符使用不当,执行过程中可能会出现软件故障。事实上,这种手动分配和释放的过程很容易出错。一些常见的编码错误包括:
- Dangling reference
- Memory leak
- 悬空参考
- 内存泄漏
尽管如此,我们更喜欢手动内存管理而不是垃圾收集,因为它给了我们更多的控制权并提供了更好的性能。请注意,任何系统编程语言的目标都是尽可能“接近金属”。换句话说,在权衡取舍中,它们倾向于更好的性能而不是便利功能。
确保不使用指向我们释放的值的指针完全是我们(开发人员)的责任。
在最近的过去,已经有几种经过验证的模式可以避免这些错误,但这一切都归结为保持严格的代码纪律,这需要始终如一地应用正确的内存管理方法。
关键要点是:
- 更好地控制内存管理。
- 由于悬空引用和内存泄漏,安全性降低。
- 导致更长的开发时间。
自动或隐式内存释放
自动内存管理已成为包括 Java 在内的所有现代编程语言的基本特征。
在自动内存释放的情况下, 垃圾收集器 充当自动内存管理器。这些垃圾收集器会定期遍历堆并回收未使用的内存块。他们代表我们管理内存的分配和释放。所以我们不必编写代码来执行内存管理任务。这很好,因为垃圾收集器将我们从内存管理的责任中解放出来。另一个优点是它减少了开发时间。
另一方面,垃圾收集有许多缺点。在垃圾收集期间,程序应该暂停并花时间确定在继续之前需要清理什么。
此外,自动内存管理具有更高的内存需求。这是因为垃圾收集器为我们执行内存释放,这会消耗内存和 CPU 周期。因此,自动内存管理可能会降低应用程序的性能,尤其是在资源有限的大型应用程序中。
关键要点是:
- 无需开发人员手动释放内存。
- 提供高效的内存安全性,没有悬空引用或内存泄漏。
- 更简单直接的代码。
- 更快的开发周期。
- 对内存管理的控制较少。
- 导致延迟,因为它消耗内存和 CPU 周期。
Rust 如何保证内存安全?
一些语言提供 垃圾收集,它在程序运行时寻找不再使用的内存;其他要求程序员 显式分配和释放内存。这两种模型都有优点和缺点。垃圾收集虽然可能是使用最广泛的,但也有一些缺点;它以牺牲资源和性能为代价,让开发人员的生活变得轻松。
话虽如此,一种提供了有效的内存管理 控制,而另 一种则 通过消除悬空引用和内存泄漏来提供更高的安全性。Rust 结合了两个世界的好处。
Rust 采用了与其他两种不同的方法,基于 所有权模型 和一组规则,编译器验证这些规则以确保内存安全。如果违反任何这些规则,程序将不会编译。事实上,所有权将运行时垃圾收集替换为内存安全的编译时检查。
习惯所有权需要一些时间,因为它对许多程序员来说是一个新概念,比如我自己。
所有权
至此,我们对数据在内存中是如何存储的有了基本的了解。让我们更仔细地看看 Rust 中的所有权 。Rust 最大的显着特点是所有权,它确保了编译时的内存安全。
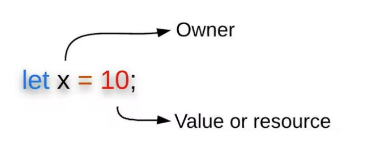
首先,让我们从最字面意义上定义“所有权”。所有权是“拥有”和“控制”合法拥有“某物”的状态。话虽如此,我们必须确定 所有者是谁 以及 所有者拥有和控制什么。在 Rust 中,每个值都有一个称为其 所有者的变量。简单来说,变量就是所有者,变量的值就是所有者拥有和控制的。
使用所有权模型,一旦拥有它的变量超出范围,内存就会自动释放(释放)。当值超出范围或它们的生命周期由于某种其他原因而结束时,它们的析构函数被调用。析构函数,尤其是自动析构函数,是一种通过删除引用从程序中删除值的痕迹并释放内存的函数。
借用检查器
Rust 通过 借用检查器实现所有权,一个 静态分析仪. 借用检查器是 Rust 编译器中的一个组件,它跟踪整个程序中数据的使用位置,并且通过遵循所有权规则,它能够确定需要释放数据的位置。此外,借用检查器确保在运行时永远不会访问已释放的内存。它甚至消除了由并发突变(修改)引起的数据竞争的可能性。
所有权规则
如前所述,所有权模型建立在一组称为 所有权规则的规则之上,这些规则相对简单。Rust 编译器 (rustc) 强制执行以下规则:
- 在 Rust 中,每个值都有一个变量,称为它的所有者。
- 一次只能有一个所有者。
- 当所有者超出范围时,该值将被删除。
以下内存错误受这些编译时检查所有权规则的保护:
- 悬空引用: 这是指向不再包含指针所指数据的内存地址的引用;此指针指向空数据或随机数据。
- 释放后使用: 这是内存被释放后访问的地方,这可能会崩溃。这个内存位置也可以被黑客用来执行代码。
- 双重释放: 这是释放分配的内存,然后再次释放的地方。这可能会导致程序崩溃,从而可能暴露敏感信息。这也允许黑客运行他们选择的任何代码。
- 分段错误: 这是程序尝试访问不允许访问的内存的地方。
- 缓冲区溢出: 这是数据量超过内存缓冲区的存储容量,导致程序崩溃的地方。
在深入了解每个所有权规则的细节之前,了解 copy、 move和 clone之间的区别很重要。
复制
具有固定大小的类型(尤其是原始类型)可以存储在 堆栈中 ,并在其作用域结束时弹出,并且如果代码的另一部分需要相同的值,则可以快速轻松地复制以创建新的独立变量不同的范围。因为复制堆栈内存既便宜又快速,因此具有固定大小的原始类型被称为具有 复制 语义。它廉价地创建了一个完美的复制品(复制品)。
值得注意的是,具有固定大小的原始类型实现了复制特征来进行复制。
let x = "hello";
let y = x;
println!("{}", x) // hello
println!("{}", y) // hello
在 Rust 中,有两种字符串:(
String堆分配的,可增长的)和&str(固定大小的,不能变异的)。
因为 x 存储在堆栈中,所以复制它的值以生成另一个副本 y 更容易。对于存储在堆上的值,情况并非如此。这是堆栈帧的外观:
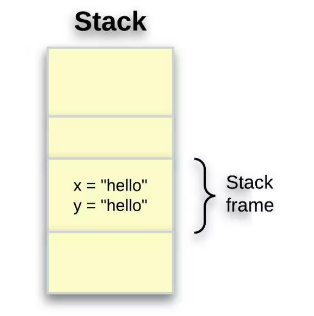
复制数据会增加程序运行时间和内存消耗。因此,复制不适用于大块数据。
移动
在 Rust 术语中,“移动”意味着将内存的所有权转移给另一个所有者。考虑存储在堆上的复杂类型的情况。
let s1 = String::from("hello");
let s2 = s1;
我们可以假设第二行(即 let s2 = s1;)将复制 in 的值 s1 并将其绑定到 s2。但这种情况并非如此。
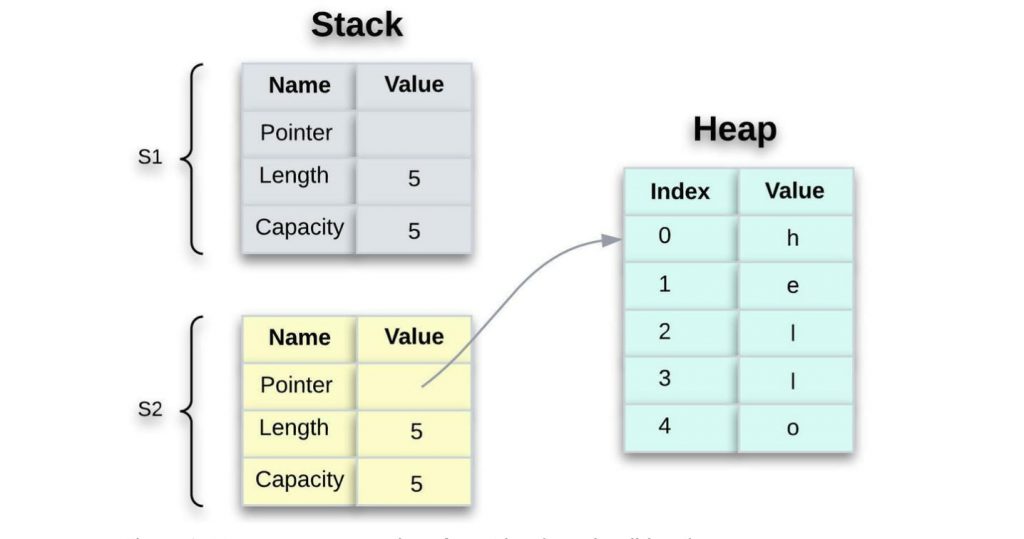
看看下面的内容,看看 String 引擎盖下发生了什么。字符串由三部分组成,存储在 堆栈中。实际内容(你好,在这种情况下)存储在 堆上。
- 指针 – 指向保存字符串内容的内存。
- 长度
String– 它 是当前正在使用 的内容的内存量(以字节为单位) 。 - 容量
String– 它是 从分配器接收到的 内存总量,以字节为单位 。
换句话说,元数据保存在堆栈上,而实际数据保存在堆上。
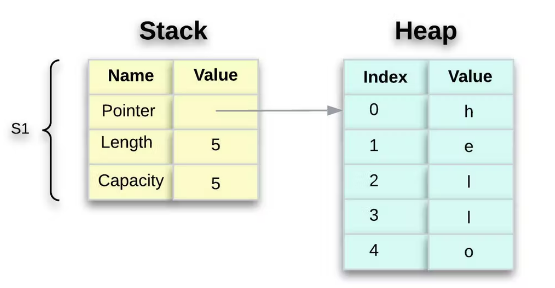
当我们分配 s1 给 时 s2, String 元数据被复制,这意味着我们复制堆栈上的指针、长度和容量。我们不会复制指针所指堆上的数据。内存中的数据表示如下所示:
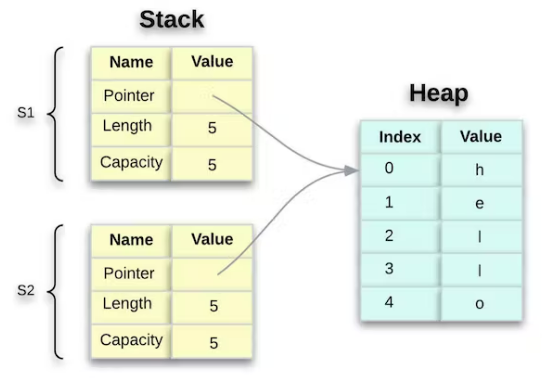
值得注意的是,这个表示 看起来不像 下面的那个,如果 Rust 也复制了堆数据,这就是内存的样子。如果 Rust 执行此 s2 = s1 操作,如果堆数据很大,则操作在运行时性能方面可能会非常慢。
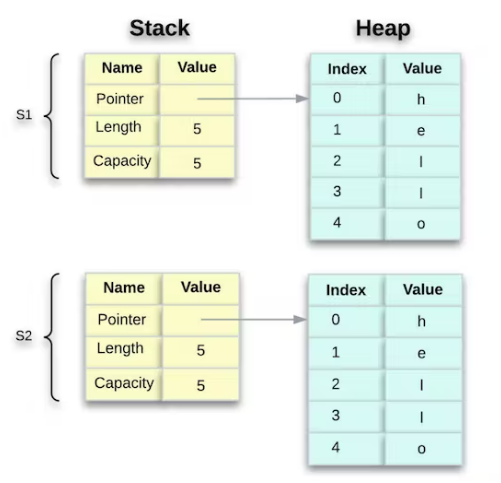
请注意,当复杂类型不再在范围内时,Rust 将调用该 drop 函数来显式释放堆内存。但是,图 6 中的两个数据指针都指向同一个位置,这不是 Rust 的工作方式。我们将很快进入细节。
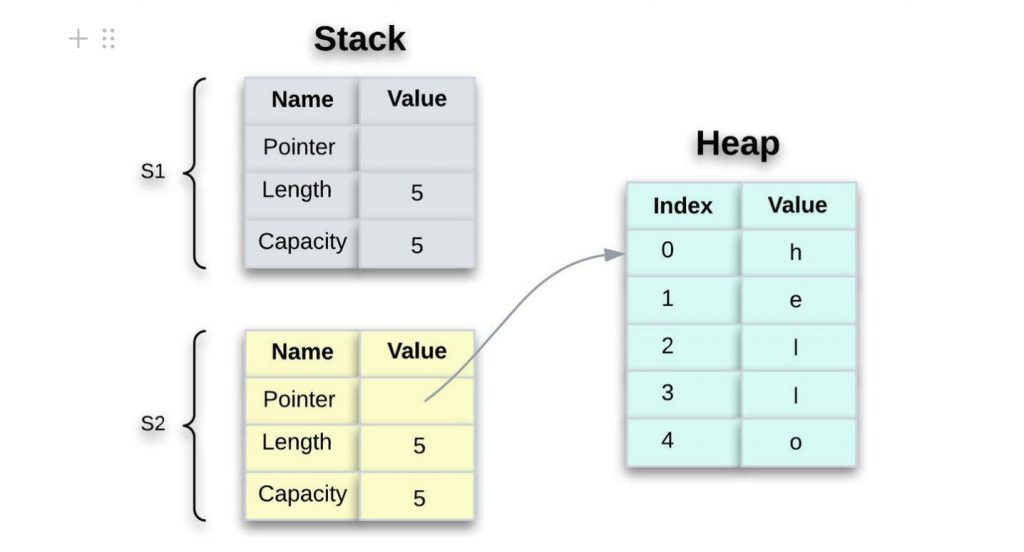
如前所述,当我们分配 s1 给 时 s2,变量 s2 会收到 s1的元数据(指针、长度和容量)的副本。但是 s1 一旦它被分配到 会发生什么s2?Rust 不再认为 s1 是有效的。是的,你没看错。
让我们考虑一下这个 let s2 = s1 任务。考虑一下如果 s1 在这个赋值之后 Rust 仍然认为是有效的会发生什么。当 s2 和 s1 超出范围时,它们都会尝试释放相同的内存。呃,那不好。这被称为 双重释放错误,它是内存安全错误之一。两次释放内存可能会导致内存损坏,从而带来安全风险。
为了保证内存安全,Rust s1 在 let s2 = s1. 因此,当 s1 不再在范围内时,Rust 不需要释放任何东西。检查如果我们 在创建s1 之后 尝试使用会发生什么s2 。
let s1 = String::from("hello");
let s2 = s1;
println!("{}, world!", s1); // Won't compile. We'll get an error.
我们将收到如下错误,因为 Rust 阻止您使用无效的引用:
$ cargo run
Compiling playground v0.0.1 (/playground)
error[E0382]: borrow of moved value: `s1`
--> src/main.rs:6:28
|
3 | let s1 = String::from("hello");
| -- move occurs because `s1` has type `String`, which does not implement the `Copy` trait
4 | let s2 = s1;
| -- value moved here
5 |
6 | println!("{}, world!", s1);
| ^^ value borrowed here after move
|
= note: this error originates in the macro `$crate::format_args_nl` (in Nightly builds, run with -Z macro-backtrace for more info)
For more information about this error, try `rustc --explain E0382`.
由于 Rust s1将内存的所有权“移动”到 s2 line 之后 let s2 = s1,它被认为是 s1 无效的。这是 s1 失效后的内存表示:
当 only s2保持有效时,它会在超出范围时单独释放内存。结果, 在 Rust 中消除了双重释放错误的可能性。那好极了!
克隆
如果我们 确实 想深入复制 的堆数据 String,而不仅仅是堆栈数据,我们可以使用一个名为 的方法 clone。以下是如何使用克隆方法的示例:
let s1 = String::from("hello");
let s2 = s1.clone();
println!("s1 = {}, s2 = {}", s1, s2);
使用 clone 方法时,堆数据确实被复制到 s2 中。这完美地工作并产生以下行为:
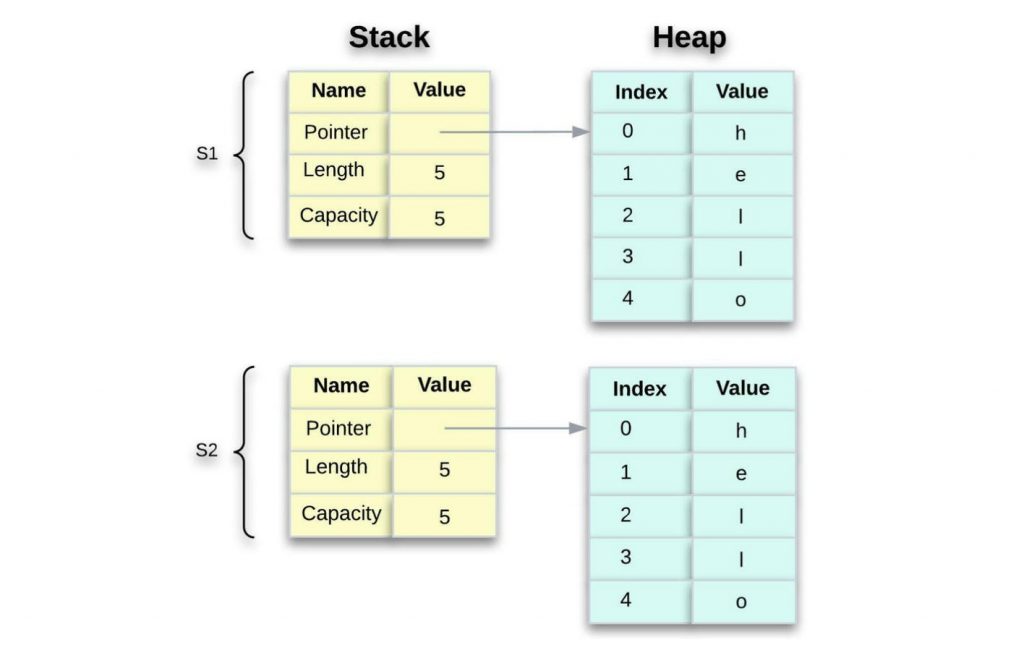
使用克隆方法后果严重;它不仅复制数据,而且不同步两者之间的任何更改。一般来说,克隆应该仔细计划并充分意识到后果。
至此,我们应该能够区分复制、移动和克隆。现在让我们更详细地了解每个所有权规则。
所有权规则 1
每个值都有一个变量,称为它的所有者。这意味着所有值都归变量所有。在下面的示例中,变量 s 拥有指向我们字符串的指针,在第二行中,变量 x 拥有值 1。
let s = String::from("Rule 1");
let n = 1;
所有权规则 2
在给定时间只能有一个值的所有者。一个人可以拥有许多宠物,但在所有权模型方面,任何时候都只有一个值 🙂

让我们看一下使用 原语的示例,这些原语在编译时是固定大小的。
let x = 10; let y = x; let z = x;
我们取了 10 个并将其分配给x; 换句话说,x拥有 10 个。然后我们x将其分配给y,我们也将其分配给z. 我们知道在给定时间只能有一个所有者,但我们在这里没有遇到任何错误。x所以这里发生的是,每次我们将它分配给一个新变量时,编译器都会复制它。
堆栈帧如下x = 10:y = 10和z = 10。然而,情况似乎并非如此:x = 10、y = x和z = x。众所周知,x10 是这个值的唯一拥有者,既不y也z不能拥有这个值。
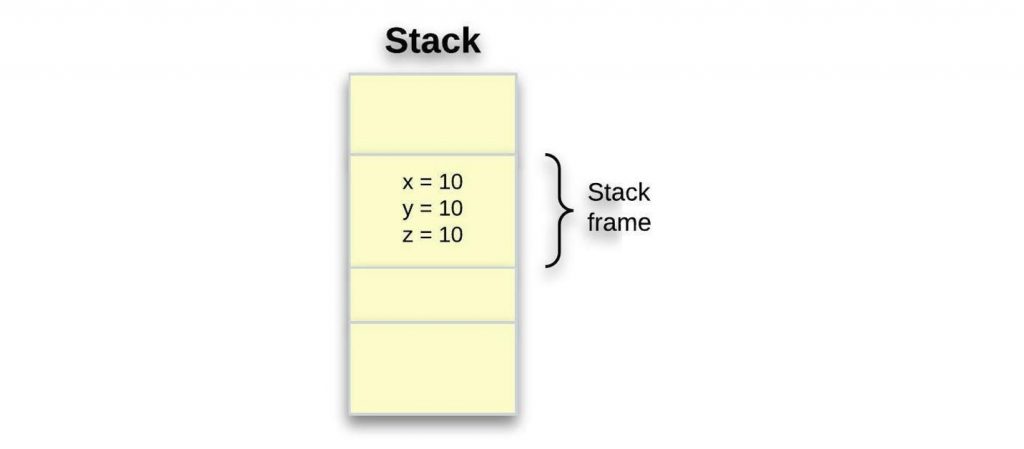
因为复制堆栈内存既便宜又快速,因此据说具有固定大小的原始类型具有 复制 语义,而复杂类型则 移动 所有权,如前所述。因此,在这种情况下,编译器会制作 副本。
此时,行为 变量绑定 类似于其他编程语言。为了说明所有权规则,我们需要一个复杂的数据类型。
让我们看看存储在堆上的数据,看看 Rust 是如何理解何时清理它的;String 类型是这个用例的一个很好的例子。我们将专注于 String 的所有权相关行为;然而,这些原则也适用于其他复杂的数据类型。
众所周知,复杂类型管理堆上的数据,其内容在编译时是未知的。让我们看一下我们之前看到的同一个例子:
let s1 = String::from("hello");
let s2 = s1;
println!("{}, world!", s1); // Won't compile. We'll get an error.
在String类型的情况下,大小可能会扩展并存储在堆上。这表示:
- 在运行时,必须从内存分配器请求内存(我们称之为第一部分)。
- 当我们完成使用 our
String时,我们需要将这个内存返回(释放)回分配器(我们称之为第二部分)。
我们(开发人员)处理了第一部分:当我们调用 时String::from,它的实现会请求它需要的内存。这部分在编程语言中几乎很常见。
但是,第二部分不同。在具有垃圾收集器 (GC) 的语言中,GC 会跟踪并清理不再使用的内存,我们不必担心它。在没有垃圾收集器的语言中,我们有责任识别何时不再需要内存并要求显式释放它。正确执行此操作一直是一项具有挑战性的编程任务:
- 如果我们忘记了,我们会浪费记忆。
- 如果我们做得太早,我们将有一个无效的变量。
- 如果我们这样做两次,我们将得到一个错误。
Rust 以一种新颖的方式处理内存释放,使我们的生活更轻松:一旦拥有它的变量超出范围,内存就会自动返回。
让我们回到正题。在 Rust 中,对于复杂类型,诸如为变量赋值、将其传递给函数或从函数返回之类的操作不会复制值:它们会移动它。简单地说,复杂类型移动所有权。
当复杂类型不再在作用域内时,Rust 将调用 drop 函数来显式地释放堆内存。
所有权规则 3
当所有者超出范围时,该值将被删除。再次考虑前面的情况:
let s1 = String::from("hello");
let s2 = s1;
println!("{}, world!", s1); // Won't compile. The value of s1 has already been dropped.
赋值给(在赋值语句中)之后的值s1已经下降。因此,在此分配后不再有效。这是删除 s1 后的内存表示:s1s2let s2 = s1s1
所有权如何变动
在 Rust 程序中,有三种方法可以将所有权从一个变量转移到另一个变量:
- 将一个变量的值分配给另一个变量(已经讨论过)。
- 将值传递给函数。
- 从函数返回。
将值传递给函数
将值传递给函数的语义类似于将值分配给变量。就像赋值一样,将变量传递给函数会导致它移动或复制。看看这个例子,它显示了复制和移动用例:
fn main() {
let s = String::from("hello"); // s comes into scope
move_ownership(s); // s's value moves into the function...
// so it's no longer valid from this
// point forward
let x = 5; // x comes into scope
makes_copy(x); // x would move into the function
// It follows copy semantics since it's
// primitive, so we use x afterward
} // Here, x goes out of scope, then s. But because s's value was moved, nothing
// special happens.
fn move_ownership(some_string: String) { // some_string comes into scope
println!("{}", some_string);
} // Here, some_string goes out of scope and `drop` is called.
// The occupied memory is freed.
fn makes_copy(some_integer: i32) { // some_integer comes into scope
println!("{}", some_integer);
} // Here, some_integer goes out of scope. Nothing special happens.
如果我们在调用 s 之后尝试使用 s move_ownership,Rust 会抛出编译时错误。
从函数返回
返回值也可以转移所有权。下面的示例显示了一个返回值的函数,其注释与上一个示例中的注释相同。
fn main() {
let s1 = gives_ownership(); // gives_ownership moves its return
// value into s1
let s2 = String::from("hello"); // s2 comes into scope
let s3 = takes_and_gives_back(s2); // s2 is moved into
// takes_and_gives_back, which also
// moves its return value into s3
} // Here, s3 goes out of scope and is dropped. s2 was moved, so nothing
// happens. s1 goes out of scope and is dropped.
fn gives_ownership() -> String { // gives_ownership will move its
// return value into the function
// that calls it
let some_string = String::from("yours"); // some_string comes into scope
some_string // some_string is returned and
// moves out to the calling
// function
}
// This function takes a String and returns it
fn takes_and_gives_back(a_string: String) -> String { // a_string comes into
// scope
a_string // a_string is returned and moves out to the calling function
}
变量的所有权始终遵循相同的模式:一个值在分配给另一个变量时被移动。除非数据的所有权已转移到另一个变量,否则当包含堆上数据的变量超出范围时,该值将被清除drop。
希望这能让我们对所有权模型是什么以及它如何影响 Rust 处理值的方式有一个基本的了解,例如将它们相互分配以及将它们传入和传出函数。
坚持,稍等。还有一件事…
与所有好东西一样,Rust 的所有权模型确实有某些缺点。一旦我们开始研究 Rust,我们很快就会意识到某些不便。我们可能已经观察到,获取所有权然后用每个函数返回所有权有点不方便。

令人讨厌的是,如果我们想再次使用它,除了该函数返回的任何其他数据之外,我们传递给函数的所有内容都必须返回。如果我们想要一个函数使用一个值而不取得它的所有权怎么办?
考虑以下示例。下面的代码将导致错误,因为一旦所有权转移给函数,最初拥有它的函数 (in )v就不能再使用变量了。mainprintln!print_vector
fn main() {
let v = vec![10,20,30];
print_vector(v);
println!("{}", v[0]); // this line gives us an error
}
fn print_vector(x: Vec<i32>) {
println!("Inside print_vector function {:?}",x);
}
跟踪所有权似乎很容易,但当我们开始处理大型复杂程序时,它会变得复杂。所以我们需要一种在不转移所有权的情况下转移价值的方法,这就是借贷概念发挥作用的地方。
借款
借,从字面意义上来说,是指接受某物并承诺归还。在 Rust 的上下文中, 借用 是一种在不声称拥有它的情况下访问价值的方式,因为它必须在某个时候归还给它的所有者。

当我们借用一个值时,我们用&操作符引用它的内存地址。A&称为参考。引用本身并没有什么特别之处——在幕后,它们只是地址。对于熟悉 C 指针的人来说,引用是指向内存的指针,其中包含属于(又名拥有)另一个变量的值。值得注意的是,Rust 中的引用不能为空。实际上,引用就是指针;它是最基本的指针类型。大多数语言中只有一种类型的指针,但 Rust 有不同类型的指针,而不仅仅是一种。指针及其各种类型是一个不同的主题,将单独讨论。
简而言之,Rust 将创建对某个值的引用称为借用该值,该值最终必须返回给其所有者。
让我们看一个简单的例子:
let x = 5;
let y = &x;
println!("Value y={}", y);
println!("Address of y={:p}", y);
println!("Deref of y={}", *y);
以上产生以下输出:
Value y=5 Address of y=0x7fff6c0f131c Deref of y=5
在这里,y变量借用了变量拥有的数字x,但x仍然拥有值。我们称之为y对 的引用x。y超出范围时借用结束,并且由于y不拥有该值,因此它不会被销毁。要借用一个值,请使用操作员的引用&。p 格式化,{:p}输出为内存位置,以十六进制表示。
在上面的代码中,“*”(即星号)是对引用变量进行操作的解引用运算符。这个解引用运算符允许我们获取存储在指针内存地址中的值。
让我们看看一个函数如何在不通过借入获得所有权的情况下使用一个值:
fn main() {
let v = vec![10,20,30];
print_vector(&v);
println!("{}", v[0]); // can access v here as references can't move the value
}
fn print_vector(x: &Vec<i32>) {
println!("Inside print_vector function {:?}", x);
}
我们将引用 ( &v) (也称为pass-by-reference)传递给print_vector函数,而不是转移所有权(即pass-by-value)。这样一来,在主函数中调用该print_vector函数后,我们就可以访问v.
使用解引用运算符跟随指向值的指针
如前所述,引用是一种指针,可以将指针视为指向存储在别处的值的箭头。考虑下面的例子:
let x = 5; let y = &x; assert_eq!(5, x); assert_eq!(5, *y);
在上面的代码中,我们创建了对i32类型值的引用,然后使用解引用运算符来跟踪对数据的引用。该变量x保存一个i32类型值,5。我们将yequal 设置为对 的引用x。
这是堆栈内存的显示方式:

我们可以断言 x 等于 5。但是,如果我们想对 in 中的值进行断言 y,我们必须遵循对它所指使用的值的引用 *y (因此在这里取消引用)。一旦我们取消引用 y,我们就可以访问指向的整数值, y 我们可以将其与 进行比较 5。
如果我们尝试改写 assert_eq!(5, y); ,我们会得到这个编译错误:
error[E0277]: can't compare `{integer}` with `&{integer}`
--> src/main.rs:11:5
|
11 | assert_eq!(5, y);
| ^^^^^^^^^^^^^^^^ no implementation for `{integer} == &{integer}`
因为它们是不同的类型,所以不允许比较数字和对数字的引用。因此,我们必须使用解引用运算符来跟随对它所指向的值的引用。
引用默认是不可变的
像变量一样,引用在默认情况下是不可变的——它可以通过 设置为可变的mut,但前提是它的所有者也是可变的:
let mut x = 5; let y = &mut x;
不可变引用也称为共享引用,而可变引用也称为独占引用。
考虑以下情况。我们授予对引用的只读访问权限,因为我们使用的是&运算符而不是&mut. 即使源n是可变的ref_to_n,并且another_ref_to_n不是,因为它们是只读的 n 借用。
let mut n = 10; let ref_to_n = &n; let another_ref_to_n = &n;
借用检查器将给出以下错误:
error[E0596]: cannot borrow `x` as mutable, as it is not declared as mutable --> src/main.rs:4:9 | 3 | let x = 5; | - help: consider changing this to be mutable: `mut x` 4 | let y = &mut x; | ^^^^^^ cannot borrow as mutable
借用规则
有人可能会质疑为什么不总是喜欢借钱而不是搬家。如果是这样,为什么 Rust 甚至有移动语义,为什么不默认借用?原因是在 Rust 中借用一个值并不总是可能的。只有在某些情况下才允许借款。
借用有自己的一套规则,借用检查器在编译期间严格执行这些规则。制定这些规则是为了防止数据竞争。它们如下:
- 借款人的范围不能超过原所有者的范围。
- 可以有多个不可变引用,但只有一个可变引用。
- 所有者可以拥有不可变或可变引用,但不能同时拥有两者。
- 所有引用都必须有效(不能为空)。
参考不能超过所有者
引用的范围必须包含在值所有者的范围内。否则,引用可能会引用一个已释放的值,从而导致释放后使用错误。
let x;
{
let y = 0;
x = &y;
}
println!("{}", x);
上面的程序尝试x在所有者y超出范围后取消引用。Rust 防止了这种释放后使用错误。
许多不可变引用,但只允许一个可变引用
我们一次可以对特定数据有尽可能多的不可变引用(也称为共享引用),但一次只允许一个可变引用(也称为独占引用)。存在此规则是为了消除数据竞争。当两个引用同时指向同一个内存位置时,其中至少有一个正在写入,并且它们的动作不同步,这称为数据竞争。
我们可以有尽可能多的不可变引用,因为它们不会更改数据。另一方面,借用限制我们一次只保留一个可变引用 ( &mut),以防止在编译时发生数据竞争的可能性。
让我们看看这个:
fn main() {
let mut s = String::from("hello");
let r1 = &mut s;
let r2 = &mut s;
println!("{}, {}", r1, r2);
}
上面尝试创建两个可变引用(r1和r2)的代码s将失败:
error[E0499]: cannot borrow `s` as mutable more than once at a time
--> src/main.rs:6:14
|
5 | let r1 = &mut s;
| ------ first mutable borrow occurs here
6 | let r2 = &mut s;
| ^^^^^^ second mutable borrow occurs here
7 |
8 | println!("{}, {}", r1, r2);
| -- first borrow later used here
闭幕致辞
希望这能澄清所有权和借款的概念。我还简要介绍了借贷检查器,它是所有权和借贷的支柱。正如我在开头提到的,所有权是一个新奇的想法,一开始可能很难理解,即使对于经验丰富的开发人员也是如此,但随着你的工作越多,它就会变得越来越容易。这只是 Rust 中如何强制执行内存安全的简要说明。我试图使这篇文章尽可能易于理解,同时提供足够的信息来掌握这些概念。有关 Rust 所有权功能的更多详细信息,请查看他们的在线文档。
当性能很重要时,Rust 是一个不错的选择,它解决了困扰许多其他语言的痛点,从而通过陡峭的学习曲线向前迈出了重要的一步。Rust连续第六年成为 Stack Overflow 最受欢迎的语言,这意味着许多有机会使用它的人都爱上了它。Rust 社区继续发展壮大。
根据 Rust 2021 年调查结果:2021 年无疑是 Rust 历史上最重要的一年。它见证了 Rust 基金会、2021 年版以及比以往任何时候都更大的社区的成立。随着我们走向未来,Rust 似乎正走在一条强大的道路上。
快乐学习!




